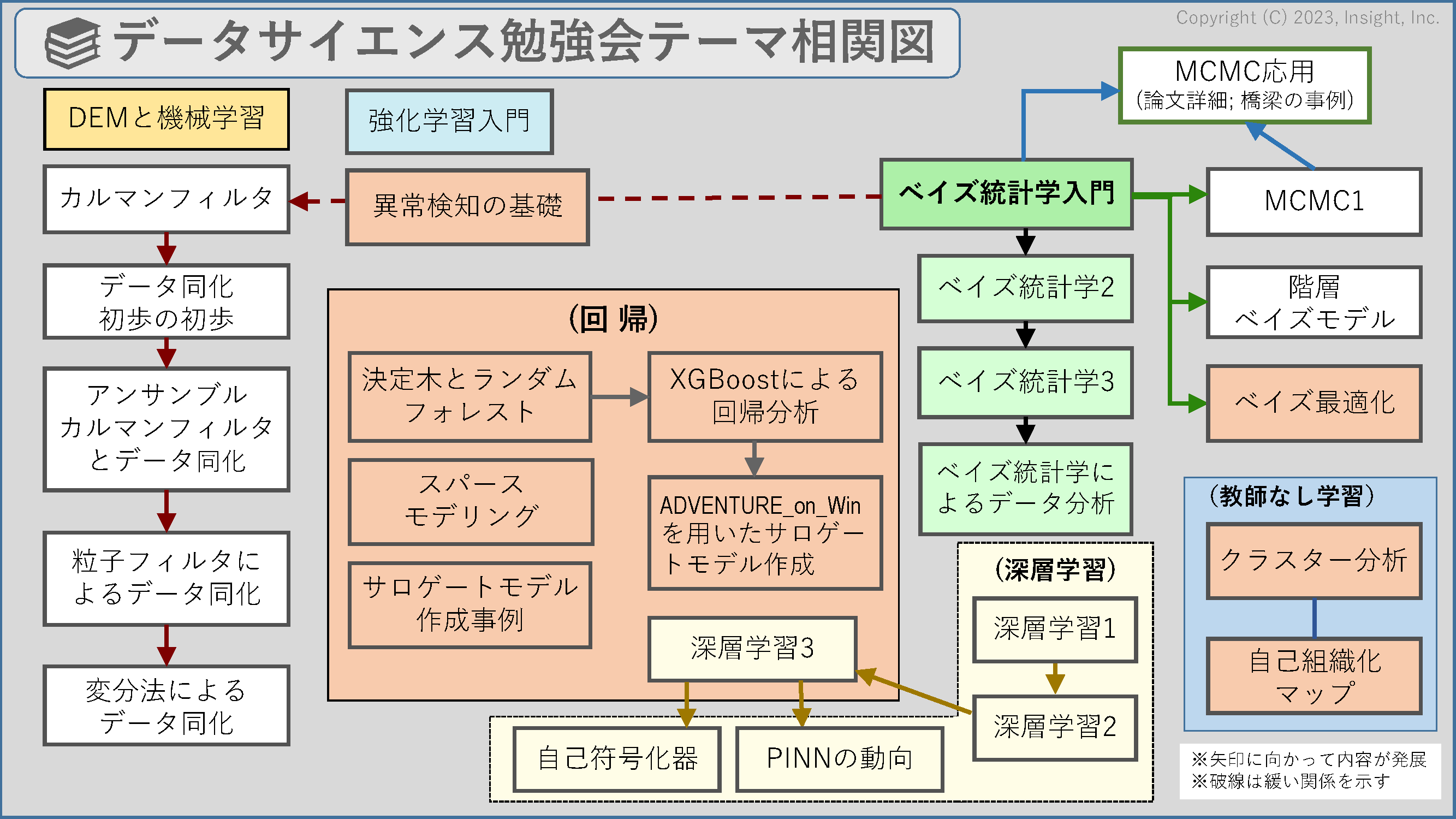
| テーマ |
内容 |
参加に必要な知識 |
| ベイズ統計学入門 |
・ベイズの理論
・ベイズの定理
・確率変数と確率分布
・離散型・連続型
・ベイズ更新
・非ベイズ
・頻度主義との比較
・適用事例
・質疑、討論
|
|
| ベイズ統計学2 |
・逆確率(5つのジャンプ)
・ベイズ学習と予測
・グラフィカルモデル
・条件付同時確率
・共役事前分布
・ケーススタディ
・不確実性に基づく意思決定
・事例(論文の背景/
結論・成果/提案の技術詳細)
・実装方法
・質疑、討論
|
「ベイズ統計学入門(旧ベイズ統計学)」に参加、またはベイズ統計学の基礎をご理解の方向け |
| ベイズ統計学3 |
・ベイズ統計学のもやもや感
・ベイズの定理の復習
・ベイズの問題設定の仕方
・ベイズの定理の利点
・ベイズ線形回帰
・ベイズ線形回帰の実装
・ハンズオンベイズ統計
・実装方法
|
「ベイズ統計学入門(旧ベイズ統計学)」に参加、またはベイズ統計学の基礎をご理解の方向け |
| ベイズ最適化 |
実験する度に今までの実験結果に基づいて“ベイズ的に”次の実験を
デザインするのがベイズ最適化です。製造業等、様々な分野で実験の
効率化を図ることが出来ると考えられています。 ガウス過程による回帰を
うまく使って、実験計画法における新しい実験候補を探索したり、
回帰モデルやクラス分類モデルのハイパーパラメータ(学習では
求まらないため事前に決めるべきパラメータ)を決定する方法です。
内容は、実験計画法、獲得関数、探索と活用のトレードオフ、ガウス過程など。
|
「ベイズ統計学入門(旧ベイズ統計学)」に参加、またはベイズ統計学の基礎をご理解の方向け |
| ベイズ最適化(ハンズオン) |
ベイズ最適化のコードをご自分で動かす事を目標とした会です。
必要に応じて、既に参加頂いた「ベイズ最適化」の復習的な内容を含みます。
環境は、原則Anacondaとします。
個人のITリテラシーの差が有りますので、他の参加者と同期する為、お待たせしたり、見切り発車する事も有り得ますが、予めご了承下さい。
※ 開発環境ツール「PyCharm Community」を使用(開催中にインストール時間を設けます)
|
過去に「ベイズ最適化」に参加された方向け。
テキストはありません。 |
| 階層ベイズ・モデル |
背景
論文紹介
階層性の有るデータ
非ベイズ回帰モデル
階層ベイズモデルの概要
標準誤差
t検定
Pythonによる実装
質疑、討論
|
「ベイズ統計学入門(旧ベイズ統計学)」に参加、またはベイズ統計学の基礎をご理解の方向け |
| ベイズ統計学によるデータ分析 |
1. 事例概要
2. 環境設定
3. ベイズ統計学を学ぶ理由
4. ライブラリ概要
5. 進め方
6. データ
7. 正規分布による推定
8. モデル
9. 事後分布の確認
10. 統計量の評価
11. 事後予測チェック
12. グループ比較
13. ベイズ型階層的線形回帰
14. 製造業への応用について
15. ソースコード
|
|
| ベイズ最適化適用事例 |
|
|
| クラスター分析 |
・クラスター分析とは
・分類の必要性・目的
・クラスター分析の方針決定
・分類 階層的手法
非階層的手法
ハードクラスタリング
ソフトクラスタリング
非類似度
クラスターの合併方法
・適用事例
・実装方法
|
|
| 自己組織化マップ |
・SOM(Self OrganizingMap)概要
・利用の目的
・深層学習におけるデータの選別と分類
・SOMの特徴・理論
・競合学習とは
・SOM生成例、アルゴリズム
・ラベリングとその注意点
・適用事例
・実装方法
|
|
| MCMC1 |
・乱数発生アルゴリズムMCMC、その利用目的
・ベイズ更新の復習
・マルコフ連鎖の例
・定常分布(=不変分布)への収束
・マルコフ連鎖の収束条件
・詳細釣り合い条件
・マルコフ連鎖モンテカルロ法
・メトロポリス・ヘイスティング(MH)法
・MH法アルゴリズム
・ハミルトニアン・モンテカルロ法
・独立MH法(ケーススタディ)
・CAEへの適応事例
・実装方法
・質疑、討論
|
「ベイズ統計学入門(旧ベイズ統計学)」に参加、またはベイズ統計学の基礎をご理解の方向け |
MCMC応用
(論文詳細;橋梁の事例) |
・マルコフ連鎖
・マルコフ連鎖モンテカルロ法
・メトロポリス・ヘイスティング(MH)法
・MH法アルゴリズム
・独立MH法
・MCMCの応用:CAEの事例
既存構造物の数値モデルの構造パラメータ
における不確定性の考慮
加振実験によるデータ取得と分析
有限要素(FE) モデルの構築
ベイズ推定とMCMCの利用
Higdonの同定方法
代替モデルの構築
事前分布の設定・推定結果
不確定性の低減
事後分布によるモデル更新
|
|
| カルマンフィルタ |
・カルマンフィルタの用途・考え方
・状態空間モデルとは
・観測方程式と状態方程式
・カルマンゲインとその計算方法
・カルマンフィルタをより
理解する為には
・確率過程と時系列データ
・白色雑音(ホワイトノイズ)と
ランダムウォーク
・ARモデル・MAモデル・ARMAモデル
・アルゴリズム
・ケーススタディ
・実装方法
・質疑応答
|
先に「ベイズ統計学入門」への参加をお勧めします。 |
| 決定木とランダムフォレスト |
・分類木/回帰木
・アンサンブル学習
・決定木の精度
・目的関数
・分割条件(エントロピー、
ジニ不純度、分類誤差)
・CAEへの適用事例
(アイデアの例示のみ)
・実装方法
・質疑、討論
|
|
| データ同化初歩の初歩 |
・データ同化とは
・ベイズ統計学の概要
・基本的な用語
・ベイズの定理
・重要な用語
・データ同化の概要
・線形最小分散推定
・状態空間モデル
・カルマンフィルタ
・統計モデルへの移行
・質疑、討論
|
「ベイズ統計学」への前もっての参加は不要です |
| アンサンブルカルマンフィルタとデータ同化 |
・データ同化とは
・ベイズの定理の復習
・データ同化の概要
・線形最小分散推定
・確率分布とデルタ関数
・データ同化とベイズ統計学
・状態空間モデル
・カルマンフィルタ
・拡張カルマンフィルタ
・Enカルマンフィルタ
・ケーススタディとソースコード
・質疑その他
|
「ベイズ統計学入門(旧ベイズ統計学)」に参加、またはベイズ統計学の基礎をご理解の方向け |
| 粒子フィルタによるデータ同化 |
・レベル1:粒子フィルタとは
・レベル2:粒子フィルタのアルゴリズム概要
・レベル3:粒子フィルタの導出
・レベル4:利点と問題点
・レベル5:実装方法
・レベル6:リサンプリングの実装
|
ベイズの定理、ベイズ更新、条件付き独立を理解されている方向け |
| 変分法によるデータ同化 |
・レベル0:線形最小分散推定(復習)
・レベル1:最尤推定
・レベル2:ベイズ推定からの導出
・レベル3:線形最小分散推定と最尤推定の比較
・レベル4:最適内挿法1
・レベル5:最適内挿法2
・レベル6:最適内挿法演習
|
|
| 異常検知の基礎 |
・基本的な考え方
・正規分布に従うデータ
・1変数正規分布
・多変量正規分布
・クラスター分析の概要
・ケーススタディ
・実装方法
・質疑、討論
|
|
| スパース・モデリング |
スパースモデリングは、一般的に無駄の多い大量のデータの中から少量の本質的なデータを抽出する技術と言われていますが、ノイズを含む画像からノイズを除去するのにも利用されています。それは正則化と言う技術を利用して実現されます。正則化の中でも特にL1ノルムを使った正則化が注目されており、LASSOと呼ばれております。スパースモデリングの成果は、MRIの画像解析や、ブラックホールの画像の高解像度化で良く知られてます。LASSOは単純に回帰の技術として利用する事も可能です。
|
|
| 深層学習1 |
・レベル1:パーセプトロン
・レベル2:パーセプトロンから階層型ニュー
ラルネットワークへ
・レベル3:活性化関数
・レベル4:2層NNの実装
・レベル5:学習の枠組み
・CAE事例紹介
・質疑、討論
|
|
| 深層学習2 |
・「深層学習1」の復習
・レベル6:学習の枠組み2
誤差低減
バッチ学習
ミニバッチ学習
オンライン学習
勾配降下法
演習
・レベル7:2層NNの学習の実装
・CAEへの適用事例
流体力学における大量データの扱い
高性能計算機と並列計算技術の発展
過去50年間のデータ処理技術の進化
データベースとアルゴリズムの開発
流体力学データ分析の課題
・質疑、討論
|
「深層学習1」に参加、もしくは同等の知識をお持ちの方向け |
| 深層学習3 |
・深層学習1で学んだ事
・深層学習2で学んだ事
・レベル8:計算グラフ
・レベル9:活性化関数
・レベル10:Affine層
・レベル11:Softmax-w-Error層
・レベル12:誤差逆伝播法の実装
・レベル13:CAE事例
|
「深層学習1」「深層学習2」に参加、もしくは同等の知識をお持ちの方向け |
| (自己符号化器) |
ANN(人工ニューラルネットワーク)の次元削減や生成モデルの概念を理解する上で自己符号化器を学ぶ事は重要です。
又、自己符号化器には、クラス分類を行う場合、生データをその対象とするよりも、次元削減されたデータを用いた方が性能が向上する等と言う利用方法が有ります。
自己符号化器の基礎理論について述べ、零からの実装コードを示す。
|
|
| XGBoostによる回帰分析 |
・決定木、分類木、回帰木について(決定木の復習)
・アンサンブル学習(特にブースティング)の概要
・勾配降下法(GBDT)の概念とアルゴリズム
・XGBoostパラメータ
・ケーススタディ 等
|
「決定木とランダムフォレスト」に参加された方または同等の知識を習得の方向け |
ADVENTURE_on_Winを用いたサロゲートモデル作成(XGBoost使用)
(旧:ADVENTURE_on_ Windowsを用いた回帰分析) |
現在日常生活や、報道等で、人工知能とかAIと言う言葉を聞かない日は有りません。
CAE技術者にも、今後はデータ駆動型の技能や知識が求められる事は、時代の趨勢から見て明らかだと言えます。
データ駆動型の技能や知識が求められるとは、CAEを用いたパラメトリックスタディや結果分析等において、機械学習や統計学を活用する事を指します。
未だ、CAE技術者の資格試験の分野として、採用されてはおりませんが、海外では既にUncertainty Quantificationと言う分野がCAEの中で確立されており、Wikipediaの見出し語にもその名が見えます。
本講習会では、CAEの中に機械学習を導入する事の事例をご紹介致します。
CAEソフトとしては、誰でも入手可能なオープンソースソフトである、Adventure_on_Windows(
https://adventure.sys.t.u-tokyo.ac.jp/jp/)を使用します。
尚、本講習会は座学のみとさせて頂きます(講師によるデモの紹介は有ります)。
|
|
| サロゲートモデル作成事例 |
1. 事例概要
2. 代理モデルの必要性
3. 降着装置の梁モデル
4. 代理モデリングの手順
5. 代理モデリング手法
6. ケーススタディ1
7. ケーススタディ2
8. 考察
9. 結論
|
|
| 強化学習入門 |
レベル1:強化学習とは
レベル2:スロットマシン問題
レベル3:報酬の期待値
レベル4:行動価値の算出
レベル5:ε-greedy戦略
レベル6:ε-greedy法の統計的特徴
レベル7:非定常問題のε-greedy法
レベル8:マルコフ決定過程
レベル9:MDPの求解
レベル10:MDP計算例
レベル11: CAE適用事例
|
|
PINNと強化学習の研究動向
【new】 |
現在CAE界で非常に注目されているPINN(Physics-Informed Neural Network)の発展は凄まじく、強形式、弱形式、エネルギー、ベイズ、逆問題、粒子法等かなりの分野で既に試されています。
その最新動向をー昨年7月に開催されたWCCM2022の論文を中心に最新の動向を調査しました。
(WCCM;World Congress on Computation Mecchanics)
|
|
| Python/Numpy基礎講習会 |
現在弊社では、CAE技術者がデータサイエンスを利用することを推進しています。
データサイエンスの処理プログラム言語は現在PythonとRが主流ですが、RからPythonへの移行が予想されます。 データサイエンスのプログラムを組む際に、計算速度の観点やライブラリを利用する為にはNumpyの利用が必須です。この講習会ではPython全般の基礎知識とNumpyに焦点を絞っています。コードを丁寧に説明します。
Python/Numpyについて
Pythonの概要
Numpyの概要
CAEへの適用事例
質疑、討論
|
|
| Pandasコーディング技術 |
1.pandasの概要
2.read_csvメソッド
3.eries
4.DataFrame
5.ictionaryの性質
6.DataFrame
7.isnullメソッド
8.fillnaメソッド
9.dropメソッド
10.groupbyメソッド
11.プロットとの組み合わせ
|
|
DEMと機械学習
(LIGGGHTS(R)-PUBLICによる粉体解析)
(旧:LIGGGHTS(R)-PUBLIC と機械学習) |
1.LIGGTHTS(R)-PUBLICの概要
2.同実行例動画の紹介
3.同データ作成方法の紹介
4.可視化方法の紹介
5.機械学習との連携
6.質疑討論
|
|
| ColaboratoryでCAE技術者の為の Python/Numpy基礎 |
|
|